Overview
Teaching: 10 min Exercises: 0 minQuestions
What do we need to know to set up a reproducible analysis workflow?
Objectives
Understand the conceptual pieces that make up reproducible research.
Learn where to go for information
You can skip this module if you can answer these questions? —>
- What elements should be captured for repeatable analysis?
- How do you annotate a CSV file for others to understand?
- How do you convert a docker container to singularity?
- How can you recreate your analysis environment on any machine?
Typical brain imaging analyses involve data, software, and human interaction to test hypotheses, explore relations in data and/or extract properties in data (e.g., data features). These analyses rely on numerous elements such as data quality, software environment, algorithms, and human input (e.g., assessment and/or curation) that can introduce errors. In order to repeat or reproduce any analysis, it is essential to record the information of each element.
An analysis workflow
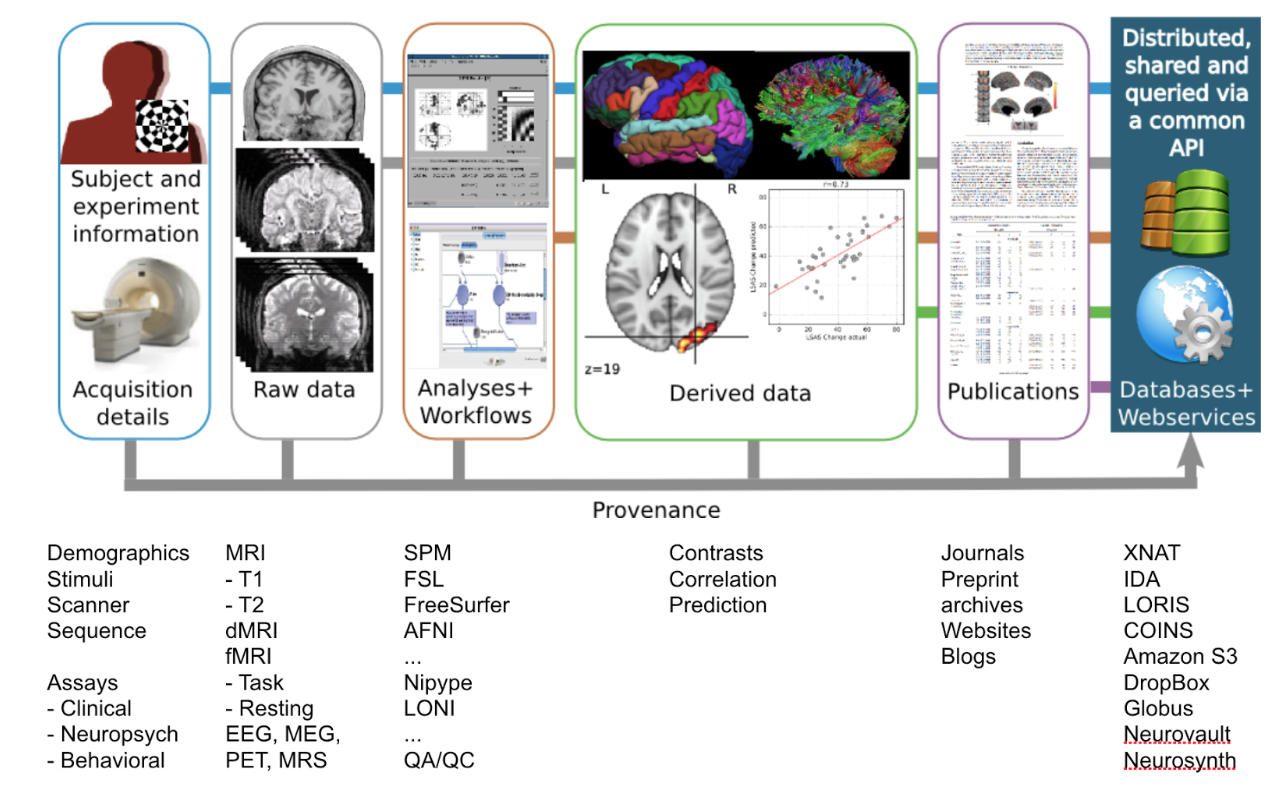
Reproducing an analysis workflow requires knowing the details of:
- Datasets used as input of the analysis, including
- steps followed to collect or find such data,
- status of data (e.g., raw/pre-processed).
- Analysis steps performed
- processing
- statistics
- Steps necessary to re-do/re-run the analysis
- Software environment used, including
- OS,
- environment (e.g., Python version, compiler version),
- specific program (version),
- dependencies.
- Steps necessary to recreate the same or similar environment
- Validation procedure (e.g., how did the researcher validate the output?)
These steps are essential for the preservation of information for future use, for the correct documentation of methods for widespread dissemination, and for the repeatability/reproducibility of the experiment by third parties.
Prerequisites
For this module, we expect the reader to be familiar with unix environments
and have a general idea of brain image analysis. We recommend that you go
through the overview lectures of the reproducible basics and FAIR data
principles modules.
What will you learn
You will learn how to set up and conduct reproducible analysis workflows, how to preserve the information, and how to share data and code with others.
How long will it take
This module consists of 6 lessons, each comprising multiple units. Each unit in this module will take you up to 10 hours of work.
Lessons included in this module
- Lesson 1. An example framework for reproducible analysis
- Lesson 2. How to annotate, harmonize, clean, and version brain imaging data
- Lesson 3. How to create and maintain reproducible computational environments for analysis
- Lesson 4. How to use dataflow tools to capture detailed provenance and perform efficient analyses
- Lesson 5. How to setup a testing framework to revalidate analyses as data and software change
- Lesson 6. How to track complete provenance of the analyses from data to results
Key Points
Reproducible research requires understanding all pieces of the (data) workflow
You should be familiar with the necessary elements and tools for reproducible analysis.