Computational basis and ReproIn/DataLad
(Neuro)Debian/Git/GitAnnex/DataLad: Distributions and Version Control
Overview
Teaching: 10 min Exercises: 30 minQuestions
What are the best ways to obtain and track information about software, code, and data used or produced in the study?
Objectives
Rehearse the knowledge of Git on how to obtain repositories locally, inspect history, commit changes
Go over basic/main commands of APT package manager for preparing computational environments
Introduction
The title for this section brings together a wide range of technologies which
are at first glance completely independent: GNU/Linux
distributions—such as Debian—which provide computing environments,
and version control systems(VCS)—such as Git—which originate in
software development. But both
distributions and version control systems have a feature in common: they
distributions and version control systems have a feature in common: they
provide means to obtain, or in other words to install, and to manage content
locally. Moreover, installed content components typically carry unambiguous
specification of the installed version and often its origin –
where it came from. It is this characteristic which makes them ideal
vehicles to be used to obtain components (code,
software, data etc.) necessary for your research instead of manually
downloading and installing them.
In this training section we will concentrate on learning only a few basic core commands for a number of popular technologies, which will help you to discover and obtain necessary for the research project components. Moreover, we will present a few features of DataLad which will be used in subsequent lectures.
This “Distributions” Google Spreadsheet provides a somewhat simplified overview and an aligned comparison of the basic concepts and commands of Debian/Conda/PyPI/Git/git-annex/DataLad if we consider their “versioned distribution” functionality. Please consult that spreadsheet to complete hands-on challenges below, before sneaking into the “full” answer.
More thorough coverage
If you are interested to learn more about VCS and Git in particular, and package managers/distributions, we encourage you to go through following materials at any other convenient moment later on your own:
(Neuro)Debian
Debian
Debian is the largest community-driven open source project, and one of the oldest Linux distributions. Its platform and package format (DEB) and package manager (APT) became very popular, especially after Debian was chosen to be the base for many derivatives such as Ubuntu and Mint. At the moment Debian provides over 40,000 binary packages virtually for any field of endeavour including many scientific applications. Any number of those packages could be very easily installed via a unified interface of the APT package manager and with clear information about versioning, licensing, etc. Interestingly, almost all Debian packages now are themselves guaranteed to be reproducible (see Debian: Reproducible Builds).
Because of such variety, wide range of support hardware, acknowledged stability, adherence to principles of open and free software, Debian is a very popular “base OS” for either direct installation on hardware, or in the cloud or containers (docker or singularity).
NeuroDebian
NeuroDebian project was established to integrate software used for research in psychology and neuroimaging within the standard Debian distribution.
To facilitate access to the most recent versions of such software on already existing releases of Debian and its most popular derivative Ubuntu, NeuroDebian project established its own APT repository. So, in a vein, such repository is similar to Debian backports repository, but a) it also supports Ubuntu releases, b) typically backport builds are uploaded to NeuroDebian as soon as they are uploaded to Debian unstable, c) contains some packages which did not make it to Debian proper yet.
To enable NeuroDebian on your standard Debian or Ubuntu machine, you could
apt-get install neurodebian (and follow the interactive dialogue) or just follow
the instructions on http://neuro.debian.net .
Exercise: check NeuroDebian
Check if NeuroDebian is “enabled” in your VM Ubuntu installation
Solution
% apt policy | grep -i neurodebian ...For those using older VM images for NeuroDebian, you might have to use
apt-cache policyinstead ofapt policy
Note: “God” privileges needed
Operations which modify the state of the system (so not just searching/showing) require super user to do it, so it is typical to have sudo tool installed, and used as a prefix to the command (e.g.
sudo do-evilto rundo-evilas super user)
Exercise: Search and Install
Goal is to search for and install application(s) to visualize neuroimaging data (using terminal for the purpose of the exercise, although there are good GUIs as well)
Question: What terms did you search for?
% apt search medical viewer Sorting... Done Full Text Search... Done aeskulap/xenial 0.2.2b1-15 amd64 medical image viewer and DICOM network client edfbrowser/xenial 1.57-1 amd64 viewer for biosignal storage files such as bdf and edf fsleyes/xenial,xenial 0.15.1-2~nd16.04+1 all FSL image viewer libvtkgdcm-tools/xenial 2.6.3-3ubuntu3 amd64 Grassroots DICOM VTK tools and utilities sigviewer/xenial 0.5.1+svn556-4build1 amd64 GUI viewer for biosignals such as EEG, EMG, and ECG% apt search nifti viewer Sorting... Done Full Text Search... Done fslview/xenial,xenial,now 4.0.1-6~nd+1+nd16.04+1 amd64 [installed] viewer for (f)MRI and DTI data% apt search fmri visual Sorting... Done Full Text Search... Done connectome-workbench/xenial,now 1.3.1-1~nd16.04+1 amd64 [installed] brain visualization, analysis and discovery tool connectome-workbench-dbg/xenial 1.3.1-1~nd16.04+1 amd64 brain visualization, analysis and discovery tool -- debug symbols fsl-neurosynth-atlas/data,data 0.0.20130328-1 all neurosynth - atlas for use with FSL, all 525 terms fsl-neurosynth-top100-atlas/data,data 0.0.20130328-1 all neurosynth - atlas for use with FSL, top 100 termsSo, unfortunately generally there is no standardized language to describe packages, but see DebTags and Debian blends task pages, e.g. Debian Med imaging packages and made from the NeuroDebian-oriented list of Software.
Install your choice
% sudo apt install XXX
Exercise: Multiple available versions
The goal of the exercise is to be able to install the desired version of a tool
How many of
connectome-workbenchyou see available?% apt policy connectome-workbench connectome-workbench: Installed: 1.1.1-1 Candidate: 1.3.1-1~nd16.04+1 Version table: 1.3.1-1~nd16.04+1 500 500 http://neuro.debian.net/debian xenial/main amd64 Packages 1.1.1-1 500 500 http://us.archive.ubuntu.com/ubuntu xenial/universe amd64 Packages 100 /var/lib/dpkg/statusInstall
1.1.1-1version of theconnectome-workbench% sudo apt install connectome-workbench=1.1.1-1For the bored/challenged: install
1.2.0-1~nd16.04+1version ofconnectome-workbench
- It is not readily available from NeuroDebian since was replaced by newer version
- There is a semi-public http://snapshot-neuro.debian.net:5002 providing snapshots of NeuroDebian
- Knock the server (run
curl -s http://neuro.debian.net/_files/knock-snapshotsin a terminal) to open access for you- Find when there was
1.2.0-1~nd16.04+1available- Add a new entry within
/etc/apt/sources.list.d/neurodebian.sources.listpointing to that snapshot of NeuroDebian APT repository- Update the list of known packages
- Verify that now it is available
- Install that version
Git
We all probably do some level of version control of our files, documents, and even data files, but without a version control system (VCS) we do it in an ad-hoc manner:
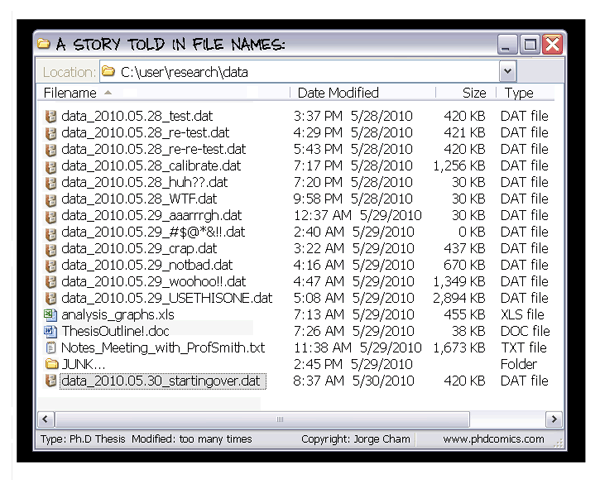
Unlike distributions (like Debian, conda, etc) where we (users) have only the power of selecting some already existing versions of software, the main purpose of VCS do not only provide access to existing versions of content, but give you the “super-power” to establish new versions by changing or adding new content. They also often facilitate sharing the derived works with a complete and annotated history of content changes.
Exercise – What is Git?
Consult
man git% man git | grep -A1 '^NAME' NAME git - the stupid content tracker
Exercise – tell Git about yourself!
Since Git makes a record of changes, please configure git to know your name and email (you could as well use fake email, just better be consistent to simplify attribution)
% git config --global user.name "FirstName LastName" % git config --global user.email "ideally@real.email"Check the content of
~/.gitconfigwhich is the--globalconfig for git.Without
--globalconfiguration changes would be stored in.git/configof a particular repository
Hint: use
git COMMAND --helpto obtain documentation specific to the
COMMAND. Recall navigation shortcuts from the previous section. Similarly--helpis available fordatalad COMMANDs.
Exercise –
installAKAcloneClone https://github.com/repronim/ohbm-training locally
Solution
I am sorry if you had to look in here ;-)
% git clone https://github.com/ReproNim/ohbm2018-training Cloning into 'ohbm2018-training'... remote: Counting objects: 194, done. remote: Compressing objects: 100% (46/46), done. remote: Total 194 (delta 31), reused 48 (delta 21), pack-reused 126 Receiving objects: 100% (194/194), 133.22 KiB | 0 bytes/s, done. Resolving deltas: 100% (84/84), done. Checking connectivity... done.
Question: What is the “version” of the content you got?
git clone brings you the most recent content available in the “default branch” of the repository. So what “version” of content did we get?
Solution(s)
Version should be something which uniquely and unambiguously describes content. In Git it would be the SHA1 checksum of the commit you got
% git show | HEAD commit 2d992fe19ccd2a1c3eb8267d9e10f6c75f190eaa Merge: 3a42dd1 012c53f Author: JB Poline <jbpoline@gmail.com> Date: Thu Jun 14 17:55:20 2018 +0800 ...But SHA1 is not “ordered”, i.e. from observing one SHA1 you cannot tell if it comes later or earlier in development of the content. git tag allows one to “tag” specific content versions with meaningful and/or comparable version strings. Run
git tagto see available tags, and then usegit describeto give unique but also ordered version of the content% git describe 0.0.20180614 # you probably get something else ;-)
Git “philosophy” in 2 minutes
- Git is a “stupid content tracker”
- “content” is files committed to git + associated metadata (author name, dates etc)
- “content” is stored under
.git/objects- Git is a distributed VCS, so all content committed to Git
is copied/cloned/duplicated (within
.git/objects) across all clones of the repository
- Git is a distributed VCS, so all content committed to Git
is copied/cloned/duplicated (within
- “content” is identified by SHA1 checksum
- branches and tags
are just references/pointers to the specific version of the content:
- branches progress forward
- tags are immutable
.git/HEADpoints to the content (SHA1) or a reference (branch) of your current “version” of the repository- commands such as git push, git fetch, git pull, etc exchange references (tags, branches, etc) and the content they point to between clones of the repository. Useful rule of thumb: git pull = git fetch + git merge Before GitHub, git fetch was the only way to check differences between local and remote version of a repository. This can be done by using git fetch to fetch changes and git diff to inspect these changes.
Exercise: Time travel through the full history of changes.
- Using
aptinstallgitk- Run
gitk --all
- Find “fix” commits
- Find commits which edited
README.md- Use git checkout to jump to some previous commit you find in the history.
- Use git status . Question: what is “detached HEAD”?
- Use
git checkout masterto come back
git-annex
git-annex is a tool which allows to manage data files within a git repository, without committing (large) content of those data files directly under git. In a nutshell, git-annex
- moves actual data file(s) under
.git/annex/objects, into a file typically named according to the checksum of the file’s content, and in its place creates a symlink pointing to that new location - commits the symlink (not actual data) under git, so a file of any size would have the same small footprint within git
- within
git-annexbranch records information about where (on which machine/clone or web URL), that data file is available from
so later on, if you have access to the clones of the repository which have the
copy of the file, you could easily
git annex get its content
(which will download/copy that file under .git/annex/objects) or
git annex drop it
(which would remove that file from .git/annex/objects).
As a result of git not containing the actual content of those large files, but
instead containing just symlinks, and information within git-annex branch, it
becomes possible to
- have very lean git repositories, pointing to arbitrarily large files
- share such repositories on any git hosting portal (e.g. github). Just do
not forget also to push
git-annexbranch which would contain information about - very quickly switch (i.e. checkout) between different states of the repository, because no large file would need to be created – just symlinks
We will have exercises working with git-annex repositories in the next section
DataLad
DataLad relies on git and git-annex to provide a platform which encapsulates many aspects from “distributions” and VCS for management and distribution of code, data, and computational environments. Relying on git-annex flexibility to reference content from the web, datalad.datalad.org provides hundreds of datasets (git/git-annex repositories) which provide access to over 12TB of neuroscience data from different projects (such as openfmri.org, crcns.org etc). And because all content is unambiguously versioned by git and git-annex there is a guarantee that the content for the same version would be the same across all clones of the dataset, regardless where content was obtained from.
DataLad embraces version control and modularity (visit poster 2046 “YODA: YODA’s organigram on data analysis” for more information) to facilitate efficient and reproducible computation. With DataLad you can not only gain access to the data resources and maintain your computational scripts under version control system, you can maintain the full record of the computation you performed in your study. Let’s conclude this section with just a very minimalistic neuroimaging study we perform while recording the full history of changes. Two sections ahead we will will go through a more complete example.
Exercise: Install a dataset
Use datalad install command to install a sample dataset from http://datasets.datalad.org/?dir=/openfmri/ds000114 :
Solution
% datalad install ///openfmri/ds000114
Exercise: Explore its history
Q1: What is its current version?
Q2: Did 1.0.0 version of the dataset follow BIDS?
Q3: What is the difference between 2.0.0 and 2.0.0+1 versions?
Task: Assuming that the dataset is also compliant with the released BIDS specification 1.0.2, fix BIDSversion field in
dataset_description.jsonand datalad save the change with descriptive messageSolution
% sed -i -e 's,1.0.0rc2,1.0.2,g' dataset_description.json % datalad save -m "Boosted BIDSVersion to 1.0.2 (no changes to dataset were needed)"
Exercise: Explore and obtain a data file
Q: Look at
sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz. What is it? Does it have content?Task: Ask
git annexabout where is the content available from% git annex whereis sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz whereis sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz (5 copies) 00000000-0000-0000-0000-000000000001 -- web 0cacbc02-5b4b-48f6-89da-10a75d3bba1a -- vagrant@nitrcce:~/ds000114 [here] 135caf6c-5166-45e8-8d46-4ff5e08985b3 -- datalad 30a3fc48-d8bf-4c77-9b0b-975a9008b2bb -- yoh@smaug:/mnt/btrfs/datasets/datalad/crawl/openfmri/ds000114 b2096681-bbfc-4e3a-a832-30d7bbf373a0 -- [datalad-archives] web: http://openneuro.s3.amazonaws.com/ds000114/ds000114_R2.0.0/uncompressed/sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz?versionId=zkpz5g077RXeD86qPj7kiQMpr5UjldwG web: http://openneuro.s3.amazonaws.com/ds000114/ds000114_R2.0.1/uncompressed/sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz?versionId=twjb5fU.KJINYUnt9x5_YGRMfYzw133I web: http://openneuro.s3.amazonaws.com/ds000114/ds000114_unrevisioned/uncompressed/sub001/anatomy/highres001.nii.gz?versionId=DpHsiEVsigDTuVOHJjQDB1yxzXvhkFYJ datalad-archives: dl+archive:MD5E-s4665038365--fa2bbc92e47d15ce399e1a6722834f68.tgz#path=ds114_R2.0.0/sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz&size=8677710 datalad-archives: dl+archive:MD5E-s4665193070--e3f00f47b231bde13fe6f2ee8f4c864d.zip#path=ds000114_R2.0.1/sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz&size=8677710 datalad-archives: dl+archive:MD5E-s4930156456--bf97c46872ce26f7e3f1e6c0a91bf252.tgz/ds114/sub001/anatomy/highres001.nii.gz#size=8677710Task: Ask
datalad(orgit-annexdirectly) to obtain this fileE.g. use datalad get command to obtain the content from one of those locations.
Exercise: Perform basic analysis and make a
runrecordUse
nib-lsfrom nibabel to get and store basic statistic on the file we just obtained in anINFO.txtfile in the top directory of the dataset. When figured out the command to run, use datalad run to actually run it so it makes a record for generatedINFO.txtfile.Solution
% datalad run 'nib-ls -s sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz > INFO.txt'Use
git log INFO.txtto see the generated commit record.
Key Points
Distribution and version control systems allow for the efficient creation of tightly version-controlled computation environments
DataLad assists in creating a complete record of changes